- Professional and Statuatory Regulatory Bodies = 13 types
- Awards = 58 types
Tuesday, 16 December 2008
DIVAS Meeting Update
Chris has provided a list of the following for drop-down lists:
DIVAS Meeting Update
Present: Ben, Sam, Shaun, Chris & Sue.
We discussed what we will be recording in the metadata file when uploading validation documents to HIVE. In addition, we discussed the 'submission form' and some the process involved in uploading and searching for documents in HIVE.
This is what we decided:
Subject (XCRI = Subject)
Level (XCRI = Level)
Validation Date (XCRI = @generated)
Face-2-Face (XCRI = AttendenceMode)
Site of Delivery (XCRI = Venue)
Form of Assessment (XCRI = AssessmentStrategy)
Mode of Delivery (XCRI = StudyMode)
Faculty/School (XCRI = TBC)
Award Title (XCRI = Title)
Professional Body / Association (XCRI = AccreditedBy)
Recording Document Types
Possibly recorded in XCRI Description – unique to the individual documents being uploaded
Pre-Validation Document Types
1. Validation Support Descriptor
2. Rational
3. Programme Specification
4. Module Descriptor
5. Handbooks
a. Award / Student
b. Module
c. Placement
d. Mentor
e. *Sue to speak to R. Bennifer about other types for Work Based Learning
6. Resources
Post-Validation Document Tyes
7. Validation Report
8. Validation Report Response
The Validation Collection
We discussed what we will be recording in the metadata file when uploading validation documents to HIVE. In addition, we discussed the 'submission form' and some the process involved in uploading and searching for documents in HIVE.
This is what we decided:
Subject (XCRI = Subject)
- Discussed use of JACs
- Decided not to use this field/element at the moment
Level (XCRI = Level)
- Chris to provide a definitive list of levels for Drop-down / Look-up List
- Multiple instances recorded
Validation Date (XCRI = @generated)
- Date to be recorded = date of validation panel
Face-2-Face (XCRI = AttendenceMode)
- Drop-down / Look-up List:
- Face-2-Face
- Distance
- Blended
Site of Delivery (XCRI = Venue)
- Multiple instances recorded
Form of Assessment (XCRI = AssessmentStrategy)
- Discuss it’s relevance for validation
- Could be useful for recording data for disability
- Decided not to use this field/element at the moment
Mode of Delivery (XCRI = StudyMode)
- Drop-down / Look-up List:
- Full Time
- Part Time
- Fast Track 2 Year
- Multiple instances recorded
Faculty/School (XCRI = TBC)
- Need to investigate this further – where to record in XCRI
- Drop-down / Look-up List:
- Faculty of Arts, Media and Design (AMD)
- Business School
- Faculty of Computing, Engineering and Technology (FCET)
- Law School
- Faculty of Health
- Faculty of Science
- Academic Development Institute (ADI)
Award Title (XCRI = Title)
- Record a String title unique to the document being uploaded
- Multiple instances recorded
Professional Body / Association (XCRI = AccreditedBy)
- Chris to provide a definitive list of levels for Drop-down / Look-up List
Recording Document Types
Possibly recorded in XCRI Description – unique to the individual documents being uploaded
Pre-Validation Document Types
1. Validation Support Descriptor
2. Rational
3. Programme Specification
4. Module Descriptor
5. Handbooks
a. Award / Student
b. Module
c. Placement
d. Mentor
e. *Sue to speak to R. Bennifer about other types for Work Based Learning
6. Resources
Post-Validation Document Tyes
7. Validation Report
8. Validation Report Response
The Validation Collection
- The documents are recorded as a collection in a ‘Catalogue’ folder in HIVE
- Currently the title of the collection / ‘Catalogue’ is largely heuristic (made up) by QIS – as evidenced in the shared QIS drive
Friday, 12 December 2008
Big Push Meeting
Have arranged a meeting between Sam & Shaun (technical / coding), myself and Chris (QI). We aim to thrash out the finer points of uploading documents to HIVE.
The main areas of interest are:
The main areas of interest are:
- Determining which parts of XCRI-CAP we are going to use / focus on
- How the validation documents are 'arranged' within HIVE - i.e use of collections & metadata & type of data to be recorded (doc type etc..)
- Discuss the technology required to upload documents with the metadata
- Exploring the search facility
Thursday, 4 December 2008
DIVAS Meeting
Had a DIVAS meeting today - all productive. I was asked to supply a short paragraph / statement about my side of the project - so here it is (I will try and strip out as much of the teccy stuff as I can):
 We had some problems matching the required document attributes with the element/fields of specific metadata schemas - such as Dublin Core and LOM. In essence, the DIVAS project needs to record some specific details - against which users could search for these documents. for example:
We had some problems matching the required document attributes with the element/fields of specific metadata schemas - such as Dublin Core and LOM. In essence, the DIVAS project needs to record some specific details - against which users could search for these documents. for example:
Currently we are working on the HIVE repository being able to mark up documents stored in it against the XCRI-CAP metadata schema.
 Essentially, HIVE requires an SDI file (XML file) to be written that tells HIVE how to generate a GUI (Graphical User Interface) - this user interface is a graphical representation of the metadata schema tree - providing the user with the field elements that make up the metadata tree and (associated with each element) the type of data you can record (see image - Dublin Core Example).
Essentially, HIVE requires an SDI file (XML file) to be written that tells HIVE how to generate a GUI (Graphical User Interface) - this user interface is a graphical representation of the metadata schema tree - providing the user with the field elements that make up the metadata tree and (associated with each element) the type of data you can record (see image - Dublin Core Example).
Sam has transformed the XCRI-CAP schema document (XSD file) into an SDI file by creating an XML instance of the XSD using XMLSpy. This has created a valid and fairly usable GUI in HIVE but the ouput XML file has a few errors - therefore some work needs to be done on correcting this.
Work continues and as long as we can generate a vliad output (XML output) that is valid for XCRI-CAP then it looks good to start uploading documents to HIVE.
 We had some problems matching the required document attributes with the element/fields of specific metadata schemas - such as Dublin Core and LOM. In essence, the DIVAS project needs to record some specific details - against which users could search for these documents. for example:
We had some problems matching the required document attributes with the element/fields of specific metadata schemas - such as Dublin Core and LOM. In essence, the DIVAS project needs to record some specific details - against which users could search for these documents. for example:- Subject
- Level
- Form of Assessment
- Prof Associated Body etc....
Currently we are working on the HIVE repository being able to mark up documents stored in it against the XCRI-CAP metadata schema.
 Essentially, HIVE requires an SDI file (XML file) to be written that tells HIVE how to generate a GUI (Graphical User Interface) - this user interface is a graphical representation of the metadata schema tree - providing the user with the field elements that make up the metadata tree and (associated with each element) the type of data you can record (see image - Dublin Core Example).
Essentially, HIVE requires an SDI file (XML file) to be written that tells HIVE how to generate a GUI (Graphical User Interface) - this user interface is a graphical representation of the metadata schema tree - providing the user with the field elements that make up the metadata tree and (associated with each element) the type of data you can record (see image - Dublin Core Example).Sam has transformed the XCRI-CAP schema document (XSD file) into an SDI file by creating an XML instance of the XSD using XMLSpy. This has created a valid and fairly usable GUI in HIVE but the ouput XML file has a few errors - therefore some work needs to be done on correcting this.
Work continues and as long as we can generate a vliad output (XML output) that is valid for XCRI-CAP then it looks good to start uploading documents to HIVE.
Wednesday, 26 November 2008
XCRI-CAP Schema in HIVE
Sam has been successful in transforming an example xml file (created from a XCRI-CAP xsd) into an SDI file for HIVE (an XML file marked-up for HIVE).
Sam is currently debugging the SDI file for validation and structure issues - in addition to making sure that the output XML file is valid for how the XCRI XML should look.
The software we are using is XMLSpy - a very useful development tool for this part of the project.
Work is continuing on refining the SDI file - in particular the issue of defining attributes for spceific elements. HIVE has a limited range of available attributes for schema elements - for example xml:lang="en-gb" is used with langstring for the title element. The problem is when XCRI refers to other attributes, for example, src / title / alt for image element or onclick attributes for x:div for description element.
Sam is currently debugging the SDI file for validation and structure issues - in addition to making sure that the output XML file is valid for how the XCRI XML should look.
The software we are using is XMLSpy - a very useful development tool for this part of the project.
Work is continuing on refining the SDI file - in particular the issue of defining attributes for spceific elements. HIVE has a limited range of available attributes for schema elements - for example xml:lang="en-gb" is used with langstring for the title element. The problem is when XCRI refers to other attributes, for example, src / title / alt for image element or onclick attributes for x:div for description element.
Monday, 24 November 2008
Mapping DIVAS Validation Document Attributes to XCRI-CAP
The following is a list of the attributes/element types that QA and the project team would like HIVE to specifically record against validations (these are also considered as the searchable elements) - possible XCRI-CAP elements are hyperlinked:
- Subject (use jacs?) http://www.xcri.org/wiki/index.php/Subject
- Level eg BA Hons http://www.xcri.org/wiki/index.php/Level
- Validation Date http://www.xcri.org/wiki/index.php/Generated
- Face-2-Face or eLearning (Distance Learning) http://www.xcri.org/wiki/index.php/AttendanceMode
- Site of Delivery http://www.xcri.org/wiki/index.php/Address
- Form of Assessment http://www.xcri.org/wiki/index.php/AssessmentStrategy
- Mode of Delivery (Part Time / Full Time / Fast Track 2 year) http://www.xcri.org/wiki/index.php/StudyMode
- Faculty/School http://www.xcri.org/wiki/index.php/Address
- Award Title http://www.xcri.org/wiki/index.php/Title
- Prof Body Associated http://www.xcri.org/wiki/index.php/AccreditedBy
Thursday, 20 November 2008
Understanding the XML
Useful link: http://www.w3schools.com/schema/schema_elements_ref.asp
I have been comparing the HIVE SDI XML file for IMS 1.3 and the XSD file.
 Interestingly - the XML (SDI) file used by HIVE does not reference the LOM 1.3 XSD URL - however this does appear in the exported metadata XML - see:
Interestingly - the XML (SDI) file used by HIVE does not reference the LOM 1.3 XSD URL - however this does appear in the exported metadata XML - see:
HIVE must have this recorded somewhere else.
This is useful to know - as I am writing (attempting to write) an SDI file (XML) for XCRI-CAP. This is a bit trickier than the LOM example as LOM is neatly linear elements (hierarchical tree - see image)
XCRI - is somewhat less linear and object led - so writing out a structured tree for it may require some interrogation to identify elements and the branches/leaves. Essentially I need to write nested tags with attributes that tell HIVE how to provide the GUI/Boxes for the data inputer.
I have been comparing the HIVE SDI XML file for IMS 1.3 and the XSD file.
Interestingly - the XML (SDI) file used by HIVE does not reference the LOM 1.3 XSD URL - however this does appear in the exported metadata XML - see:HIVE must have this recorded somewhere else.
This is useful to know - as I am writing (attempting to write) an SDI file (XML) for XCRI-CAP. This is a bit trickier than the LOM example as LOM is neatly linear elements (hierarchical tree - see image)
XCRI - is somewhat less linear and object led - so writing out a structured tree for it may require some interrogation to identify elements and the branches/leaves. Essentially I need to write nested tags with attributes that tell HIVE how to provide the GUI/Boxes for the data inputer.
Exploring the XCRI Markup
See: http://wiki.teria.no/confluence/display/CIF/xcri-properties
See: http://www.bsi.mmu.ac.uk/courses/ects_example_rgu.xml
XCRI Documents
See: http://www.bsi.mmu.ac.uk/courses/ects_example_rgu.xml
XCRI Documents
"An XCRI-CAP XML document MUST have one of the following resources as its root element:From: http://www.xcri.org/wiki/index.php/XCRI_Course_Advertising_Profile#About
* Catalog
* Provider
* Course
In general any provider SHOULD use Catalog as the root element.
The specification allows both Provider and Course as alternative root elements to enable REST-style operations to be provided by aggregators (much in the same way that the IETF Atom specification enables both feed and entry elements to be document roots).
Resources
A resource is something that can be uniquely identified [1]. In XCRI, we identify resources using a Uniform Resource Identifier (URI). A resource can possess a number of properties, which may be simple value-strings or can be structured.
XCRI-CAP specifies the following resource classes:
* catalogs advertise providers
* providers advertise courses
* courses are presented for enrolment any number of times through presentations
* presentations instantiate courses
Inheritable property values
Some elements may be inferred from their presence in a containing resource when not present in child objects. Specifically:
- Where a presentation does not contain a venue, an Aggregator SHOULD assume that the venue details (name, address, email, fax, phone, url, image) are exactly the same as the properties of the provider. An Aggregator MAY assume that the description is the same as that of the provider.
- Where a course does not contain an image, but its containing provider does, an Aggregator MAY use the image of the provider when displaying the course.
- Where a presentation does not contain an applyTo property, or a qualification does not contain an awardedBy and/or accreditedBy property, an aggregator SHOULD interpret this as meaning the capability is provided by the provider and use its contact information.
This enables XCRI documents to be less verbose by not repeating basic information"
Wednesday, 19 November 2008
Creating a XCRI-CAP GUI for HIVE

I have been interrogating the xml (SDI file) for the current IMS schema in HIVE.
In simple terms, the XML file appears to be a modified file, which is marked up against the HIVE syntax/markup - this markup outlines not only the schema hierarchy tree elements but also how they are presented to the metadata inputer.
 The example I have here show the XML file in Dreamweaver and how it is represented in HIVE.
The example I have here show the XML file in Dreamweaver and how it is represented in HIVE.
Tuesday, 18 November 2008
XCRI-CAP & HIVE
If and when we decide to use XCRI-CAP as the metadata schema for HIVE (and this is not certain) we will have to 'configure' HIVE to accept this schema. This may be a simple process, but will require 'defining' the schema through creating an SDI file, which also assists in generating the GUI interface.
From HIVE admin guide:
From HIVE admin guide:
"Chapter 3: Creating an SDI File
Hive imports, exports and stores metadata in XML format.
Standards bodies such as IMS, SCORM, and Learning Federation express the format of the metadata using an XML schema file. The actual metadata is stored in an XML instance file that can be validated against the schema file.
When a Hive user opens the Edit Metadata dialog, Hive dynamically generates a user interface into which the metadata is entered. From the user’s perspective, the format of the dialog closely matches the metadata format as published by the standards body.
As published by the standards body, the metadata XML schema file does not contain all of the information needed to generate the user interface. This extra information must be placed into a Structure Definition Instance (SDI) file. The SDI file is an XML instance file.
The SDI file contains:
- Titles and descriptions of data items that are displayed on the GUI.
- The type of field into which the data must be entered, for example, a single-line text entry field or date field.
- The maximum number of characters that can be entered into a field.
- Information that specifies whether the field is mandatory or optional.
- Information that specifies whether multiple versions of the field are allowed."
XCRI-CAP
XCRI-CAP (Course Advertising Profile)
http://www.xcri.org/wiki/index.php/XCRI_Wiki
In essence the XCRI-CAP can be used to describe the courses being validated:
"A resource is something that can be uniquely identified [1]. In XCRI, we identify resources using a Uniform Resource Identifier (URI). A resource can possess a number of properties, which may be simple value-strings or can be structured.
XCRI-CAP specifies the following resource classes:
* catalogs advertise providers
* providers advertise courses
* courses are presented for enrolment any number of times through presentations
* presentations instantiate courses "
See: http://www.xcri.org/wiki/index.php/XCRI_Course_Advertising_Profile#Namespace
Monday, 17 November 2008
JISC Project Meeting: Chelsea
Had a very useful and interesting meeting with JISC & other project groups.
Was interested to hear of the experiences of metadata schema related to validations and course descriptions from:
They had experience of developing and using the XCRI schema for course descriptions. This appears to be a more appropriate schema for this project (I hope) - I will investigate further.
Further to this - Staffs had it's own project associated with XCRI = http://www.staffs.ac.uk/xcri/
UPDATE
Spoke to project lead Peter Moss associated with staffsXCRI project. Main thrust of feedback was the difficult nature of the task. Insofar that the data is simply not collected in a way as to be extracted for XCRI - too much complexity to represent.
Doesn't bode well for DIVAS - however it was noted that the metadata being collected for DIVAS is at QA Validation, therefore, there could be a new precedence for collecting data against set elements at the validation stage. This in turn could be available for re-purposing for course description purposes.
Was interested to hear of the experiences of metadata schema related to validations and course descriptions from:
- Dr. Mark Stubbs = MMU http://www.xcri.org/Welcome.html
- C. Frost & J. Hughes = Bolton Uni
They had experience of developing and using the XCRI schema for course descriptions. This appears to be a more appropriate schema for this project (I hope) - I will investigate further.
Further to this - Staffs had it's own project associated with XCRI = http://www.staffs.ac.uk/xcri/
UPDATE
Spoke to project lead Peter Moss associated with staffsXCRI project. Main thrust of feedback was the difficult nature of the task. Insofar that the data is simply not collected in a way as to be extracted for XCRI - too much complexity to represent.
Doesn't bode well for DIVAS - however it was noted that the metadata being collected for DIVAS is at QA Validation, therefore, there could be a new precedence for collecting data against set elements at the validation stage. This in turn could be available for re-purposing for course description purposes.
Monday, 10 November 2008
Back on track
After the set-back that was Microsoft Word badly marking up documents to create xml - I have been looking at how best to store/record/markup the documents using the LOM schema (through alternative data entry methods). Myself and Sam have met with Chris again to establish how the validation process handles these documents and how/why/where/what is recorded within the process.
We have a further meeting today to pin down exactly what LOM fields are being used and the method through which documents will be uploaded to HIVE and retrieved from it.
We have a further meeting today to pin down exactly what LOM fields are being used and the method through which documents will be uploaded to HIVE and retrieved from it.
Thursday, 9 October 2008
Extending the LOM
Yes - seems possible to extend the LOM to create new elements - but also keeping some 'standard' metadata.
See: http://www.imsglobal.org/metadata/mdv1p3pd/imsmd_bestv1p3pd.html#1622010
See: http://www.inigraphics.net/press/topics/2004/issue6/6_04a04.pdf
Presentation: http://www.jisc.ac.uk/uploaded_documents/jpm_lomcore.ppt
See: http://www.imsglobal.org/metadata/mdv1p3pd/imsmd_bestv1p3pd.html#1622010
See: http://www.inigraphics.net/press/topics/2004/issue6/6_04a04.pdf
Presentation: http://www.jisc.ac.uk/uploaded_documents/jpm_lomcore.ppt
Wednesday, 8 October 2008
Possible problem with Word XML
Annoyingly I have noticed that Word repeats parent element tags when you mark up - even elements that should be declared once.
This is annoying as it breaks the element tree - but both Word and HIVE seem to validated it fine!!!
See: http://www.snee.com/bobdc.blog/2007/05/word_2003s_awful_xml_for_index.html
Oh well - may be something to repair here!!
Will investigated.
This is annoying as it breaks the element tree - but both Word and HIVE seem to validated it fine!!!
See: http://www.snee.com/bobdc.blog/2007/05/word_2003s_awful_xml_for_index.html
Oh well - may be something to repair here!!
Will investigated.
Thursday, 2 October 2008
Similiar Project Reflections
 See: http://metadata.cetis.ac.uk/usage_survey/cs_hlsi.pdf
See: http://metadata.cetis.ac.uk/usage_survey/cs_hlsi.pdf"Use is made of granularity (vocabulary is {object, page, document} ) although this information is not stored in the IMS metadata record. The materials are stored in folder systems to represent the hierarchy. i.e. document folders contain pages and pages contain objects."
An interesting comment - may be worth looking into doing this for this project - as we have the option - see image.
Their specific reflections (I have experienced some of this too)
"Several versions of the IMS specification were looked at during the course of the project. Some problems with the specification were:
Examples
The examples given for how to use the elements were unclear,
particularly in the earlier documentation.
Best Practice Guidelines
There were not enough best practice guidelines.
Unclear Explanations
The catalog entry field caused some confusion initially. It was unclear if catalog and catalog entries were to be used for external searching.
New Versions
The IMS specification changed several times during the course of the project. It is quite difficult to automate the processes of upgrading and downgrading, particularly when vocabularies changed and when the specification changed to allow more than one lifecycle contributor."
Annotation 8.0 Element in LOM
This is a recommended element for the following purposes:
"This category provides comments on the educational use of this learning object, and information on when and by whom the comments were created. This category enables educators to share their assessments of learning objects, suggestions for use, etc."
"Implementers and educators SHOULD aspire to using the annotation category elements as they have the potential to significantly enhance the richness of the metadata instance by recording additional qualitative and quantitative information about the resource and its usage."
8.1 Entity = Entity (i.e. people, organisation) that created this annotation.
8.2 Date = Date that this annotation was created.
8.3 Description = The content of this annotation.
This may be very valuable in collecting the specific details of the validation document.
"This category provides comments on the educational use of this learning object, and information on when and by whom the comments were created. This category enables educators to share their assessments of learning objects, suggestions for use, etc."
"Implementers and educators SHOULD aspire to using the annotation category elements as they have the potential to significantly enhance the richness of the metadata instance by recording additional qualitative and quantitative information about the resource and its usage."
8.1 Entity = Entity (i.e. people, organisation) that created this annotation.
8.2 Date = Date that this annotation was created.
8.3 Description = The content of this annotation.
This may be very valuable in collecting the specific details of the validation document.
Wednesday, 1 October 2008
Hidden Knowledge
See: http://www.idi.ntnu.no/~lfedvard/phd/Webist_presentation.ppt
This is a very good presentation about the issues of metadata and some associated issues.
Mapping the Document fields to metadata - useful diagram
http://upload.wikimedia.org/wikipedia/commons/1/14/LOM_base_schema.png
Link to understanding metadata LOM fields
http://www.cetis.ac.uk/profiles/uklomcore/uklomcore_v0p3_1204.doc
** Back to DIVAS after working on start of term jobs - VLE **
This is a very good presentation about the issues of metadata and some associated issues.
Mapping the Document fields to metadata - useful diagram
http://upload.wikimedia.org/wikipedia/commons/1/14/LOM_base_schema.png
Link to understanding metadata LOM fields
http://www.cetis.ac.uk/profiles/uklomcore/uklomcore_v0p3_1204.doc
** Back to DIVAS after working on start of term jobs - VLE **
Monday, 8 September 2008
Some Success!!
 After some weeks of searching, experimenting and generally (seemingly) getting nowhere, If have finally (thanks to JISC forums & Sam Rowley) have worked out a way to get Word docs marked up against a Metadata Schema and an XML files created - which can then be used to populate Metadata field in the HIVE repository.
After some weeks of searching, experimenting and generally (seemingly) getting nowhere, If have finally (thanks to JISC forums & Sam Rowley) have worked out a way to get Word docs marked up against a Metadata Schema and an XML files created - which can then be used to populate Metadata field in the HIVE repository.After last week's meeting, it was agreed that we would use/explore the IEEE LOM metadata scheme for learning items.
See: http://standards.ieee.org/reading/ieee/downloads/LOM/lomv1.0/xsd/
Marking up Word docs for Metadata (XML)
 I was working on applying a schema to a Word doc for the purpose of marking up in order to create an xml file from it. Thankfully, I managed to get Word to recognize and validate the schema I was trying to use in Word. I managed to get this to work by downloading all the xsd files from the IEEE standards website and recreating the file structure (as referenced in the xsd files too) in my local drive - see image right.
I was working on applying a schema to a Word doc for the purpose of marking up in order to create an xml file from it. Thankfully, I managed to get Word to recognize and validate the schema I was trying to use in Word. I managed to get this to work by downloading all the xsd files from the IEEE standards website and recreating the file structure (as referenced in the xsd files too) in my local drive - see image right.To apply a schema - go to 'Tools' > 'Templates and Add-ins' > 'Add Schema' (Word 2003)
It is a bit buggy (I don't know whether the LOM schema are written well) - anyway to get around problems of Word not finding missing 'namespaces' or some not being declared well - I used the following in conjunction with the primary lom.xsd:
- extend\custom.xsd
- unique\loose.xsd
- vocab\loose.xsd
To start - apply the schema to the whole document - then highlight text and select the LOM element it is to be marked up with.
 One thing of note - Word does not like you to have any extraneous text/data in the Word doc before you 'save-as' XML doc (save data only). If you do not want the bother with removing this 'extra text/data' - you can force Word to save the XML file without validating the schema (see XML options). This doesn't seem to compromise the process of using this XML file to populate the Metadata fields when uploading a document to HIVE (using the Harvest Road Explorer 3.0 screen).
One thing of note - Word does not like you to have any extraneous text/data in the Word doc before you 'save-as' XML doc (save data only). If you do not want the bother with removing this 'extra text/data' - you can force Word to save the XML file without validating the schema (see XML options). This doesn't seem to compromise the process of using this XML file to populate the Metadata fields when uploading a document to HIVE (using the Harvest Road Explorer 3.0 screen).The schema type I told HIVE I was supplying is IMS 1.3.
The image supplied shows the validation screen in Word for the XML metadata bindings - the 'X' logo indicates that there is a validation issue - this disappears when you get rid of the extra 'un-marked-up' text/data.
If you want more details about this 'uploading' of files to Hive using Harvest Road Explorer and the XML files - please see previous Blog entries.
Friday, 29 August 2008
Extracting Data from Word
 A bit of a 'interesting' aside today - looking at a 'low-cost' process for exporting some data from Word files.
A bit of a 'interesting' aside today - looking at a 'low-cost' process for exporting some data from Word files.Marking up Word Docs
As part of my investigation into meta-data, Chris Gray has sent 20 Programme Specification documents to look at. One key issue is the related to consistency, in so much as the data entered is either missing (not known or required) or is not in a set format.
 In response to this, in order to get consistency there may be a need to review the data and process it for purpose. Luckily, word does allow areas of text to be marked up using XML tags and then the whole document saved as an xml 'data file'.
In response to this, in order to get consistency there may be a need to review the data and process it for purpose. Luckily, word does allow areas of text to be marked up using XML tags and then the whole document saved as an xml 'data file'.The Marking up process
[1] Firstly, an xsd file needs to be created - this is a XML Schema file that contains the elements of the schema to be used for marking up (sadly I cannot find a Dublin Core version - so I am using one that I have written myself) - ProgSpec.xsd.
 [2] Open a Word file then go to Tools > Templates and Add-ins > XML Schema Tab > add schema
[2] Open a Word file then go to Tools > Templates and Add-ins > XML Schema Tab > add schemaApply the schema to the whole document. After this - it is a simple act of just highlighting the text of the document then selecting which element in the schema tree it is to be marked up with.
Once the document has been marked up - saved it as an xml file, but make sure you select 'save data only' as this removes all presentation information that Word generates.
 When you view this document in a web browser - you will see the 'pure' data that you have marked up.
When you view this document in a web browser - you will see the 'pure' data that you have marked up.What this file gives you is an xml document that can be used to extract data from.
This process would obviously be a lot easier (and not necessary) if the document was already marked up.
Tuesday, 19 August 2008
MetaData Schema Are Not Neutral
Choosing which meta-data scheme to use is still proving difficult, as it seems very difficult to work out how to use it - am still quite keen on building my own using DC.
Interesting article: 'Metacrap: Putting the torch to seven straw-men of the meta-utopia'
Interesting article: 'Metacrap: Putting the torch to seven straw-men of the meta-utopia'
Representing the collection
 One aspect of the validation process that needs to be reflected in the repository is that it is a collection of documents. How we record this is important. as noted in previous meetings - using the category function is not appropriate as this can only be used if the 'taxonomy' is not going to change - not something that is possible for faculties, subjects etc..
One aspect of the validation process that needs to be reflected in the repository is that it is a collection of documents. How we record this is important. as noted in previous meetings - using the category function is not appropriate as this can only be used if the 'taxonomy' is not going to change - not something that is possible for faculties, subjects etc..In regard to the validation collections - Chris Gray said that he organised them by creating folders given the name of the title of the award and the date - e.g. MA Media Management 02/06/08 - into which each put all related documents.
In this folder there could then be sub-folders related to the types of documents - namely Pre-Val, Val Report and Post-Val.
Therefore, the key metadata to collect here is:
Collection Title: e.g MA Media Management
Pre-Validation Document: e.g. Programme Specification (possibly one of many docs)
Validation Panel Document: e.g. Validation Report (possibly only one)
Post-Validation Document: e.g. Amended Student Handbook (possibly one of many docs)
Based on this idea - for each and every document recorded in the collection, you would enter the following metadata:
- Programme Title
- University Faculty / School
- Method of Delivery
- Final Award
- Mode of Attendance
- TheSiS / Award Code
- Teaching Institution
- Accreditation / Professional / Statutory Body
- Date of Production (validation)
The 'Final Award' (supra-level) + 'Programme Title' + 'Date of Production' could be used to create the 'Collection Title'. Therefore - the example given would be MA Media Management 02/06/08. Recorded against each and every document being uploaded.
In respect to the type of document being uploaded - something would need to be recorded to state whether they were a 'Pre-Validation' or a 'Post Validation' submitted document - or even recorded as a 'Validation Panel' Document.
Hive Explorer
 Have been looking at Hive Explorer (a cut down Hive interface).
Have been looking at Hive Explorer (a cut down Hive interface).One feature I looked at was the 'import from file' option in the metadata section of the upload screen.
It turns out that you can create an xml file (referencing a metadata scheme) that contains the metadata you want to record for the document you are uploading.
 You can use this as the metadata data input for your file.
You can use this as the metadata data input for your file.Why is this interesting?
From a purely technical an implementation perspective - we now know that Hive can access a document and use it to populate metadata fields. This means that if you can generate an xml file that contains the metadata you want to capture - there is a 'relatively' simple process available to upload this data at this same time as uploading a document.
 Once uploaded - view the metadata for the field using 'Export Item Metadata' option. This loads an xml view for the document in a web browser - and this should match what was written in the xml docuent that was uploaded with the document.
Once uploaded - view the metadata for the field using 'Export Item Metadata' option. This loads an xml view for the document in a web browser - and this should match what was written in the xml docuent that was uploaded with the document.

How useful this is will become clearer in time....work continues....
Contact from Andy Powell Re: DC Metadata
An email from Andy Powell - regarding extending the Dublin Core Metatdata tree for this project:
Ben,
I no longer work at UKOLN and I no longer have much to do with metadata so this is a brief response.
Looking at your list of properties none look like they are sub-properties of the DC 15 with the exception of Validation Date.
On that basis, I would create a whole new set of properties using a namespace called something like 'qa' (for which you will need to assign a URI (e.,g. http://purl.org/qa/)).
Suggested properties listed below:
> 1 Teaching Institution (e.g. Staffordshire University, SURF, UK Non-SURF, Overseas) qa:teachingInstitution (http://purl.org/qa/teachingInstitution) - note URLs for further properties follow this format
> 2 Accreditation / Professional / Statutory Body qa:statutaryBody
> 3 Final Award (e.g. CertHE, BA, BA (Hons), BSc) qa:finalAward
> 4 Programme Title qa:programmeTitle
> 5 UCAS Code(s) qa:UCASCode
> 6 QAA Subject Benchmarking Group(s) qa:QAASubjectBenchmarkingGroup
> 7 Date of Production (validation date) qa:dateValidated
> 8 University Faculty / School qa:facultyOrSchool
> 9 Mode of Attendance / Delivery Method (e.g. Part Time / Full Time)qa:modeOfAttendance
> 10 Method of Delivery (e.g. Blended, Distance, Face-2-Face)qa:methodOfDelivery
> 11 THESIS / Award course code qa:courseCode
These properties need to be declared using RDFS (along the same lines as the DCMI properties at http://purl.org/dc/terms/) with dataValidated flagged as a subproperty of dcterms:date. You can put the RDFS anywhere you like, then set up the http://purl.org/qa/ URL to redirect to that place.
Hope this helps,
Andy
Although good to know - could be more work than necessary.
Ben,
I no longer work at UKOLN and I no longer have much to do with metadata so this is a brief response.
Looking at your list of properties none look like they are sub-properties of the DC 15 with the exception of Validation Date.
On that basis, I would create a whole new set of properties using a namespace called something like 'qa' (for which you will need to assign a URI (e.,g. http://purl.org/qa/)).
Suggested properties listed below:
> 1 Teaching Institution (e.g. Staffordshire University, SURF, UK Non-SURF, Overseas) qa:teachingInstitution (http://purl.org/qa/teachingInstitution) - note URLs for further properties follow this format
> 2 Accreditation / Professional / Statutory Body qa:statutaryBody
> 3 Final Award (e.g. CertHE, BA, BA (Hons), BSc) qa:finalAward
> 4 Programme Title qa:programmeTitle
> 5 UCAS Code(s) qa:UCASCode
> 6 QAA Subject Benchmarking Group(s) qa:QAASubjectBenchmarkingGroup
> 7 Date of Production (validation date) qa:dateValidated
> 8 University Faculty / School qa:facultyOrSchool
> 9 Mode of Attendance / Delivery Method (e.g. Part Time / Full Time)qa:modeOfAttendance
> 10 Method of Delivery (e.g. Blended, Distance, Face-2-Face)qa:methodOfDelivery
> 11 THESIS / Award course code qa:courseCode
These properties need to be declared using RDFS (along the same lines as the DCMI properties at http://purl.org/dc/terms/) with dataValidated flagged as a subproperty of dcterms:date. You can put the RDFS anywhere you like, then set up the http://purl.org/qa/ URL to redirect to that place.
Hope this helps,
Andy
Although good to know - could be more work than necessary.
Friday, 8 August 2008
The technical soultion
Technical meeting - identifying use-cases and current practices
Attended: Chris Gray, Sam Rowley, Song Y and Myself.
We looked at how the current validation documents were submitted, recorded (stored) and used by the QA dept.
We discussed the feasibility using a program to 'extricate' and extract key words from the validation documents to assist in completing the task of entering key metadata that needs to be recorded by the DIVAS system. Essentially, the key document of interest is the 'Programme Specifications', which has some key fields that match the type of metadata that needs recording:
If this is technically possible, the idea is to use this functionality to populate fields in an interface that can be used to assist someone in uploading documents to HIVE. This interface would therefore assist the user in completing the following tasks:
Back to the LOM?
For some weeks I have been looking at the most appropriate/useful metadata scheme to use (in conjunction with HIVE). After my meeting with library colleagues, it was noted that using a simple scheme was appropriate, so it was assumed that Dublin Core may be the most useful. However, with the team now looking at using the API functionality of HIVE - it could be argued that through using a simple interface we can use a more complex scheme (like LOM) that offers a greater range of fields/attributes to use - as the user would not be intimidated by all the fields that needed to be populated (many of which would be extranious and confusing). I will look into which LOM fields could be used to record the key metadata for the project.
Work in progress
Useful report: Nine questions to guide you in choosing a metadata schema
Attended: Chris Gray, Sam Rowley, Song Y and Myself.
We looked at how the current validation documents were submitted, recorded (stored) and used by the QA dept.
- Historically documents were submitted in a paper format (in a box file) - these recorded and stored in the QA dept.
- Recently, validation documents were also submitted in an electronic format and these were stored in a shared drive. The folder structure for this was by faculty >> award code.
- We decided that trying to replicate this in the repository would not be appropriate or necessary - principally as faculties and organizational structures change. However, it was worth recording the faculty name in the metadata (somewhere) was useful for searching purposes - as it would be a key searchable field. The use case would be a user finding validations that were submitted by faculty.
- In resepct to the documents that are collected, these would be:
- Programme Specifications
- Handbook (Student and Award)
- Module Descriptor
- Mentor Handbook (Foundation Degrees)
- Validation Report (often in pdf format)
- Generic Validation Support Documents (could be multiple instances)
- Essentially, we noted that the key documentation of interest would be associated with validations that had been successful (not that un-successful validations wouldn't be interesting - it was just an issue of ethics). With this in mind, the QA documents could be 'graded' into the following 'types:
- Pre-Validation Documents (originally submitted)
- Validation Report (conditions for success)
- Post-Validation Documents (amended for success)
We discussed the feasibility using a program to 'extricate' and extract key words from the validation documents to assist in completing the task of entering key metadata that needs to be recorded by the DIVAS system. Essentially, the key document of interest is the 'Programme Specifications', which has some key fields that match the type of metadata that needs recording:
- Awarding Body
- Teaching Institution
- Accreditation by Professional / Statutory Body
- Final Awards
- Programme Title
- UCAS Codes (possibly not required for metadata)
- QAA Subject Benchmarking Group (possible not required for metadata)
- Date of Production
- University Faulty / School
- Method of Delivery (Face-2-Face, Blended
- Mode of Attendance / Delivery Method (e.g. PT / FT)
- TheSiS / Award Code
If this is technically possible, the idea is to use this functionality to populate fields in an interface that can be used to assist someone in uploading documents to HIVE. This interface would therefore assist the user in completing the following tasks:
- Input and record the key metadata for the validation documents (for all documents)
- Upload documents (as though they were a collection), also indicating which were 'Pre' and 'Post' validation documents (along with the main validation document)
Back to the LOM?
For some weeks I have been looking at the most appropriate/useful metadata scheme to use (in conjunction with HIVE). After my meeting with library colleagues, it was noted that using a simple scheme was appropriate, so it was assumed that Dublin Core may be the most useful. However, with the team now looking at using the API functionality of HIVE - it could be argued that through using a simple interface we can use a more complex scheme (like LOM) that offers a greater range of fields/attributes to use - as the user would not be intimidated by all the fields that needed to be populated (many of which would be extranious and confusing). I will look into which LOM fields could be used to record the key metadata for the project.
Work in progress
- Understanding and exploring the API functionality of HIVE for the purposes of creating a user friendly way of interacting with HIVE - to complete the following tasks:
- Uploading documents into HIVE
- Searching of HIVE
- Embedding an API for HIVE in NING
- Uploading documents into HIVE
- Investigating how to extracate data from word documents
- Investigate the LOM scheme for HIVE - what needs to be recorded
Useful report: Nine questions to guide you in choosing a metadata schema
Building a solution
A week of meetings
Have had a good run of meetings with colleagues about this project - the result of which has been an emergent solution to the requirements - with the following dimensions:
The 2nd meeting so far and very useful in moving things forward. In terms of what was discussed, the following was highlighted:
Have had a good run of meetings with colleagues about this project - the result of which has been an emergent solution to the requirements - with the following dimensions:
- Technical
- Social / Community of Practice
- QA processes
- User / Outputs
The 2nd meeting so far and very useful in moving things forward. In terms of what was discussed, the following was highlighted:
- A lot of the 'value' delivered by the project can be delivered through the community of practice application (NING). Essentially, the meta-data is limited in what it can capture, mainly due to the data being validation specific and too varied to be isolated. Fundamentally, the metadata is useful in top-level searching of validation documents, but the 'hidden' value can really only be discussed in a more text friendly environment.
- The NING social network (and events) will allow people to offer support along side the outputs of the validation process.
- The issue of document findability was raised (as it is a key concern) and the method through which it can be presented to users (through NING?). The technical members identified a case to investigate the HIVE API functionality to offer a customizable solution to presenting search data. (See http://en.wikipedia.org/wiki/API)
- The HIVE API was offered as something which would be useful to investigate, not only for this project, but as a exercise that would be useful in exploring the capabilities of the repository. In addition, this API approach would also be useful in simplifying the process of how metadata is collected and recorded against any uploaded documents.
- The purpose or 'vision' of the project was discussed - aiming to identify some over-arching requirements for the project, in terms of what outputs are required to be successful - i.e. what a a good solution would look like. It was noted that a good solution would involve matching current QA processes (in regard to recording documentation/findability); having a system that can be 'interrogated' by a user in order to find validation examples that match their area of interest (this would include a 'list' of related documents to that specific validation); and, a search tool that could be embedded or available within the 'context' of a supportive social network.
- A further meeting was agreed between Sam Rowley, Song Ye, Myself and Chris Gray - to discuss QA processes, technical requirements and use-case scenarios.
Friday, 1 August 2008
Finding the value (Distilling)
Recording the 'value' found in the validation documents is quite difficult. One of the main problems is knowing what the value really is. On one level - the validation documents, particularly the reports, are full of text-based information that are context specific, so the issue here is one of qualifying the information and quantifying how it should be represented.
Reviewing selected 'authentic' documents
I have received some selected validation documents to review. These documents include validation report documents and the originally submitted material. From my initial assessment, it would appear that most have issues very specific to the validation process that would be difficult to categorise for the casual reviewer. However, in terms of some broad themes, these come under the following headings/categories:
In terms of where to go next - the question is how to collect 'keywords' or headings that would be helpful in identifying the validation report as something which has some specific issues of interest. This could be done by 'atomising' these headings into some sub-keywords/sub-headings - but this wuold require creating some numerous metadata fields to complete.
In terms of value - the community of practice social site would be useful in 're-purposing' and presenting these documents, and thus may offer more of a value-adding exercise than relying on keywords etc - which are in essence only valuable in respect to findability and 'marking-up' the documents for interest to the user (to investigate further - drilldown).
Work continues.....
Reviewing selected 'authentic' documents
I have received some selected validation documents to review. These documents include validation report documents and the originally submitted material. From my initial assessment, it would appear that most have issues very specific to the validation process that would be difficult to categorise for the casual reviewer. However, in terms of some broad themes, these come under the following headings/categories:
- Student Handbook Revisions
- Module Handbook Revisions
- Module Descriptors Revisions
- Some specific Blackboard VLE issues to resolve
In terms of where to go next - the question is how to collect 'keywords' or headings that would be helpful in identifying the validation report as something which has some specific issues of interest. This could be done by 'atomising' these headings into some sub-keywords/sub-headings - but this wuold require creating some numerous metadata fields to complete.
In terms of value - the community of practice social site would be useful in 're-purposing' and presenting these documents, and thus may offer more of a value-adding exercise than relying on keywords etc - which are in essence only valuable in respect to findability and 'marking-up' the documents for interest to the user (to investigate further - drilldown).
Work continues.....
Wednesday, 23 July 2008
Post-Meeting Thoughts
Meeting with - Paul Johnson (Subject & Learning Support Librarian) / Ian Haydock (Information Systems Manager)
Overview of the meeting: a general open meeting about metadata and the concepts of the project. There was an element of scoping the project with some input from their experiences from their own work with metadata.
 They agreed that the following approaches may prove useful:
They agreed that the following approaches may prove useful:
 Searchable Tag Clouds (see image left)
Searchable Tag Clouds (see image left)
Tagging has a a few issues, not least that tagging can be person and context specific. It was suggested that it may be necessary ask validation authors to enter keywords on the documents (aiding data entry for future documents). This solution is useful - especially if you ask users to select keywords from a library (similar to a category list). This challenges the issues associated with tagging synonyms - where 2 users may enter 2 different words but describing the same attribute - for example- Blue vs. Azure. One additional concern is that recommended tag 'keywords' must be developed as extensively as possible at the start of the project - as retrospective tagging will be resource intensive.
Findability
It was discussed that some work may be necessary to develop a search form that allows users to interrogate the HIVE database - for example offering a series of 'keywords' to search against (known tag cloud) - or allow them to 'drill-down' using the faculty school structure.
Additional comment
It was mentioned that documents could have an expiry date - so it may be worth investigating whether validation documents have a 'use-by' date in respect of them reflecting current validation policies and procedures.
What next?
Overview of the meeting: a general open meeting about metadata and the concepts of the project. There was an element of scoping the project with some input from their experiences from their own work with metadata.
 They agreed that the following approaches may prove useful:
They agreed that the following approaches may prove useful:- Organising a database structure for the documents in HIVE (see image) - representing the collection (e.g. folder and sub-folder structure that reflects faculties and depts.)
- Using Dublin Core Schema (simple) for top level searching of docs.
- For 'value' and textual searches - developing a tagging cloud for the document (entered in the 'Subject and Keywords' meta tag element - see image below)
- Using the relation meta tag to link 'process' documents
 Searchable Tag Clouds (see image left)
Searchable Tag Clouds (see image left)Tagging has a a few issues, not least that tagging can be person and context specific. It was suggested that it may be necessary ask validation authors to enter keywords on the documents (aiding data entry for future documents). This solution is useful - especially if you ask users to select keywords from a library (similar to a category list). This challenges the issues associated with tagging synonyms - where 2 users may enter 2 different words but describing the same attribute - for example- Blue vs. Azure. One additional concern is that recommended tag 'keywords' must be developed as extensively as possible at the start of the project - as retrospective tagging will be resource intensive.
Findability
It was discussed that some work may be necessary to develop a search form that allows users to interrogate the HIVE database - for example offering a series of 'keywords' to search against (known tag cloud) - or allow them to 'drill-down' using the faculty school structure.
Additional comment
It was mentioned that documents could have an expiry date - so it may be worth investigating whether validation documents have a 'use-by' date in respect of them reflecting current validation policies and procedures.
What next?
- Speak to current or experienced members of staff who have been involved in the validation process - asking them about how their experiences of it.
- Examine historic validation documents to build up a picture of categories and associated keywords that could be used to reflect the value of the documents (for example - common issues that validation panels encounter) - this has been started and is on-going
A question of drill-down
[Note: Back from leave]
I am going to have a meeting today with some library staff members about the issues of meta-data. One interesting point I will raise will be about whether meta-data is relevant for the purposes of this project. This may be an odd thing to say - but in terms of what the project is trying to do - it is worth noting that we are trying to 'record' the value of documents and not just catalogue them. This means that the data will be largely 'unknown' and 'fuzzy' - as it will be case-specific. Therefore, designing or using a strict metadata schema could prove difficult. However, we could still use some basic elements of the meta-data schema to record key document attributes - with half a mind to record 'flexible' data in more string/text-based elements (such as 'description'. I already alluded to this an as approach in my previous entry - through using tags (from slowly built up tag library) that you can use - delimited by a semicolon.
I will see what the library staff think about this.
In terms of drill-down - you could search for key metadata fields first and then through the use of tags use search query strings (text) such as contain "x" AND "x" NOT "x" - to find specific documents. Again - as stated in the previous post - simpler but not an elegant solution,
I am going to have a meeting today with some library staff members about the issues of meta-data. One interesting point I will raise will be about whether meta-data is relevant for the purposes of this project. This may be an odd thing to say - but in terms of what the project is trying to do - it is worth noting that we are trying to 'record' the value of documents and not just catalogue them. This means that the data will be largely 'unknown' and 'fuzzy' - as it will be case-specific. Therefore, designing or using a strict metadata schema could prove difficult. However, we could still use some basic elements of the meta-data schema to record key document attributes - with half a mind to record 'flexible' data in more string/text-based elements (such as 'description'. I already alluded to this an as approach in my previous entry - through using tags (from slowly built up tag library) that you can use - delimited by a semicolon.
I will see what the library staff think about this.
In terms of drill-down - you could search for key metadata fields first and then through the use of tags use search query strings (text) such as contain "x" AND "x" NOT "x" - to find specific documents. Again - as stated in the previous post - simpler but not an elegant solution,
Thursday, 3 July 2008
Simplicity Over Elegancy?
Have had some useful feedback via the JISC Repositories mail lists - some direct feedback and some information through reading threads.
Using Standard Metadata Schema
It seems useful (based on research) that using an already standard metadata schema will prove more helpful than trying to develop anything myself. It will still be the case that, after reviewing validation documents, it will be a task to work out which of the schema will offer the elements that are most useful to the project - for example Dublin Core vs LOM.
A issue of harvesting
One issue that has come out through comments/research is related to harvesting and presenting this data (from searches). This has a baring on what elements are to be used in a schema (some elements will/may be redundant) as this will influence how searchable the documents will be (insofar as the users can search for the 'value' in the documents).
There is an issue related to elegancy, in that (in terms of library standards) it is good practice to create or use elements that relate to the data you want record. The alternative is to use more 'semantic' keywords in a text string (for example in the element) that allows the metadata inputter to put in 'tags' that offer an insight into the 'valuable' content held in the document.
For example:
<--subject--> Geography;<--/subject-->
<--description-->Validation Report;
<--keywords-->staff development issue; handbook improvement issue; <--/keywords-->
<--relation-->http:/hiverepository/3347.doc (a related document = the orginal handbook)
This alternative is not necesarily a poor alternative as the harvester (program) can search through the schema elements for words entered into a search (text) string. The harvester itself only then uses the metadata schema elements as mark-up to assist in presenting the data fields to the user - much like database fields would be - for example, php apache online database search. This would be useful when linking documents together.
The user then has the flexibility to search semantically - for example "Geography validation report and handbook issues" if they were looking for a document that outlined a Geography validation process that encountered an issue with their handbook. The search would produce the document and 'hopefully' show a link to the related original handbook.
The only issue with this approach is that a 'tag' cloud needs to be available - that is a list of keywords that exist, which will help the user know what types of 'tags' exist (aiding searches).
Using Standard Metadata Schema
It seems useful (based on research) that using an already standard metadata schema will prove more helpful than trying to develop anything myself. It will still be the case that, after reviewing validation documents, it will be a task to work out which of the schema will offer the elements that are most useful to the project - for example Dublin Core vs LOM.
A issue of harvesting
One issue that has come out through comments/research is related to harvesting and presenting this data (from searches). This has a baring on what elements are to be used in a schema (some elements will/may be redundant) as this will influence how searchable the documents will be (insofar as the users can search for the 'value' in the documents).
There is an issue related to elegancy, in that (in terms of library standards) it is good practice to create or use elements that relate to the data you want record. The alternative is to use more 'semantic' keywords in a text string (for example in the
For example:
This alternative is not necesarily a poor alternative as the harvester (program) can search through the schema elements for words entered into a search (text) string. The harvester itself only then uses the metadata schema elements as mark-up to assist in presenting the data fields to the user - much like database fields would be - for example, php apache online database search. This would be useful when linking documents together.
The user then has the flexibility to search semantically - for example "Geography validation report and handbook issues" if they were looking for a document that outlined a Geography validation process that encountered an issue with their handbook. The search would produce the document and 'hopefully' show a link to the related original handbook.
The only issue with this approach is that a 'tag' cloud needs to be available - that is a list of keywords that exist, which will help the user know what types of 'tags' exist (aiding searches).
Getting real: getting to grips with the problem domain
I have spent the last couple of weeks researching the following key areas:
Contacting external agencies for existing real-world case studies
I contacted and had a reply back from Prof. Balbir Barn (a leading researcher into metadata and business processes) . I asked him about whether he was aware of any schema that would assist in meeting the challenges of this project. Although he could not give me any specific information, he provided links to the following projects:
Getting to grips with the problem domain
I have requested some 'real' validation documents from Chris Gray. I will be reviewing these documents and assessing the 'value' that is contained within them - which will hopefully offer some guidance on the nature of the metadata that needs to be represented to the user.
Following this, there could be the case for using these findings and asking academics / participants in the validation process to have their input into what metadata is to be recorded.
For note, I have joined the JISC repositories mail list.
- HIVE - digital repository
- Metadata schema for digital repositories
- XML mark-up language for Metadata
Contacting external agencies for existing real-world case studies
I contacted and had a reply back from Prof. Balbir Barn (a leading researcher into metadata and business processes) . I asked him about whether he was aware of any schema that would assist in meeting the challenges of this project. Although he could not give me any specific information, he provided links to the following projects:
- JISC: COVARM
- JISC: P-SPEX
- Report: Managing quality and improving efficiency in the course validation process
Getting to grips with the problem domain
I have requested some 'real' validation documents from Chris Gray. I will be reviewing these documents and assessing the 'value' that is contained within them - which will hopefully offer some guidance on the nature of the metadata that needs to be represented to the user.
Following this, there could be the case for using these findings and asking academics / participants in the validation process to have their input into what metadata is to be recorded.
For note, I have joined the JISC repositories mail list.
Wednesday, 18 June 2008
Ben: Mapping the MetaData
Useful ref: Using Dublin Core Scheme (some examples of what data to enter)
Aggregation of elements by purpose:
Content: Coverage, Description, Type, Relation, Source, Subject & Title
Intellectual Property: Contributor, Creator, Publisher & Rights
Instantiation: Date, Format, Identifier & Language
Graphical version of mapping (possible matches):


Aggregation of elements by purpose:
Content: Coverage, Description, Type, Relation, Source, Subject & Title
Intellectual Property: Contributor, Creator, Publisher & Rights
Instantiation: Date, Format, Identifier & Language
Graphical version of mapping (possible matches):


Friday, 13 June 2008
Possible MetaData Limitations in HIVE
After some extensive research and testing in HIVE, it appears that there might be an issue in trying to 'ask' HIVE to acknowledge that a document (object) is part of a collection of objects - the idea of a validation document being part of a larger validation process.
The principle issue (which may still be resolved) is that you can use metadata fields such as 'relate' (Dublin Core DC scheme) to establish a link between documents (relationship), but when you search for a document, HIVE has no facility to represent this relationship to the user - insofar as there is not a 'plus' sign logo that enlightens the user to other related documents (that are related but they might not have directly searched for).
The 'relate' (DC) should allow the reference between documents using terms such as 'ispartof' 'isrelatedto' - A reference to a related resource.
So to clarify - you can reference other documents but with no facility to represent this relationship (only an alphabetized list is produced) - you will only know of this relationship if you were the one that created it and searched for it through the metadata search facility.
I will endeavor to ascertain whether this situation can be resolved in the future as I am currently using a HIVE test server.
In the time being, I will continue to look at mapping the required document metadata to established metadata standards schema used by HIVE.
The principle issue (which may still be resolved) is that you can use metadata fields such as 'relate' (Dublin Core DC scheme) to establish a link between documents (relationship), but when you search for a document, HIVE has no facility to represent this relationship to the user - insofar as there is not a 'plus' sign logo that enlightens the user to other related documents (that are related but they might not have directly searched for).
The 'relate' (DC) should allow the reference between documents using terms such as 'ispartof' 'isrelatedto' -
So to clarify - you can reference other documents but with no facility to represent this relationship (only an alphabetized list is produced) - you will only know of this relationship if you were the one that created it and searched for it through the metadata search facility.
I will endeavor to ascertain whether this situation can be resolved in the future as I am currently using a HIVE test server.
In the time being, I will continue to look at mapping the required document metadata to established metadata standards schema used by HIVE.
Thursday, 12 June 2008
OAI Dublin Core MetaData Scoping
Link: http://dublincore.org/documents/dces/
A 'simpler' scheme in HIVE for inputting metadata as it uses only 15 elements with no sub divisional elements.
May be worth pursuing - the following useful elements exist:
1.0 Title Automatically populate field with "Item's Title" in HIVE
2.0 Creator
3.0 Subject and Keywords
4.0 Description Automatically populate field with "Item's Description" in HIVE
5.0 Publisher Automatically populate field with "BEGIN:VCARD\nFN:Name of Item's Author\nEND:VCARD" in HIVE
6.0 Contributor
7.0 Date Automatically populate field with "Item's Date of Publication" in HIVE
8.0 Resource Type
9.0 Format Automatically populate field with "Item's MIME type" in HIVE
10.0 Resource Identifier Automatically populate field with "Quick Fetch Link to Item" in HIVE
11.0 Source
12.0 Language Automatically populate field with "Item's Content Language" in HIVE
13.0 Relation
14.0 Coverage
15.0 Rights Management
Further research - link about metadata: http://www.rsp.ac.uk/repos/metadata
Further research - link about metadata schema: http://www.rsp.ac.uk/usage/metadata
A 'simpler' scheme in HIVE for inputting metadata as it uses only 15 elements with no sub divisional elements.
May be worth pursuing - the following useful elements exist:
1.0 Title Automatically populate field with "Item's Title" in HIVE
2.0 Creator
3.0 Subject and Keywords
4.0 Description Automatically populate field with "Item's Description" in HIVE
5.0 Publisher Automatically populate field with "BEGIN:VCARD\nFN:Name of Item's Author\nEND:VCARD" in HIVE
6.0 Contributor
7.0 Date Automatically populate field with "Item's Date of Publication" in HIVE
8.0 Resource Type
9.0 Format Automatically populate field with "Item's MIME type" in HIVE
10.0 Resource Identifier Automatically populate field with "Quick Fetch Link to Item" in HIVE
11.0 Source
12.0 Language Automatically populate field with "Item's Content Language" in HIVE
13.0 Relation
14.0 Coverage
15.0 Rights Management
Further research - link about metadata: http://www.rsp.ac.uk/repos/metadata
Further research - link about metadata schema: http://www.rsp.ac.uk/usage/metadata
Wednesday, 11 June 2008
Ben: Aligning Metadata Templates to Learning Objects
Worth reviewing: What is IEEE Learning Object Metadata / IMS Learning Resource Metadata?
Have been entering some test documents on HIVE - what I have discovered is that on first impression HIVE populates some basic LOM attribute metadata fields - standard and key data. However, HIVE does allow the entry of data related to all the Root, Branch and Leaf hierarchy of elements in the LOM data model - after uploading.
This facility is useful - as metadata output is an inter-operable standard XML markup for re-purposing in any delivery system.
Future development work:
Have been entering some test documents on HIVE - what I have discovered is that on first impression HIVE populates some basic LOM attribute metadata fields - standard and key data. However, HIVE does allow the entry of data related to all the Root, Branch and Leaf hierarchy of elements in the LOM data model - after uploading.
This facility is useful - as metadata output is an inter-operable standard XML markup for re-purposing in any delivery system.
Future development work:
- Upload more documents and link them in HIVE to show 'aggregation' (related to validation process) - key to searchability/findability of documents and related processes
- Match the elements of the LOM / Metadata schemes to the attributes that are required to represent the metadata for the validation documents - may require non-standard fields to be created - specific to the project. his process would require an amended XML file to be imported to HIVE (easily achieved)
Friday, 6 June 2008
Ben: Scoping Meta-Data [update]
Have had a brief (informal) meeting with Sam Rowley about XML Meta-Data templates for HIVE. He assured me that many of the templates use some (not all) of the attributes available for that template.
With this in mind - it seems that there is a possibility to match the validation process 'key' data with attribute fields that already exist in specific XML templates. This would allow the validation documents (learning objects) to be marked up for the repository and then be available for 're-purposing' in other systems (IEEE standards for interoperability). In addition, there is an option to 'link' documents through relationship data. This is useful for searching - as it should help complete aggregated searches for all related documents - representing the validation process.
Images - types of meta-data templates in HIVE / Types of attribute fields (example for IMS 1.2.1)

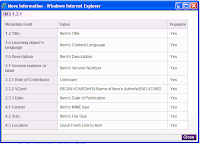
With this in mind - it seems that there is a possibility to match the validation process 'key' data with attribute fields that already exist in specific XML templates. This would allow the validation documents (learning objects) to be marked up for the repository and then be available for 're-purposing' in other systems (IEEE standards for interoperability). In addition, there is an option to 'link' documents through relationship data. This is useful for searching - as it should help complete aggregated searches for all related documents - representing the validation process.
- See wiki entry for IEEE 1484.12.1 – 2002 Standard for Learning Object Metadata
- See IEEE website for a breakdown of this standard
- See Metadata for Learning Resources: An Update on Standards Activity for 2008 (thanks to Fleur Corfield for this resource)
Images - types of meta-data templates in HIVE / Types of attribute fields (example for IMS 1.2.1)


Thursday, 5 June 2008
Ben: Scoping the MetaData
Quick introduction of my role
I will be working on structuring and distilling validation outputs for the repository.
QAA documents worth reviewing:
Had a brief meeting with Chris Gray today - an introduction meeting. We discussed the issue of identifying what appropriate meta-data fields should be created/used - based on what attributes (data fields) are collected during the validation process. One issue is the value of this data/information to the user - in respect to the fact that the user will be interested in the whole process of validation - how it was originally submitted, reviewed and then finally approved:
Key Meta-Data (requirements engineering)
The 'key' meta-data, for the time being, is the top level data about the documents - a good starting point is generic data collected through the Programme Specification Pro-Forma (Word): (the following includes possible additions suggested during the meeting)
Recording Best Practice (eLearning Models)
This is an important part of the project and further discussions are required to establish what meta-data field(s) are required to disclose the type of eLearning model(s) that were used to inform the validation process - critical when looking at creating a 'fast-track' approach for courses that engage with technology supported learning (TSL).
Next steps
I will be working on structuring and distilling validation outputs for the repository.
QAA documents worth reviewing:
Had a brief meeting with Chris Gray today - an introduction meeting. We discussed the issue of identifying what appropriate meta-data fields should be created/used - based on what attributes (data fields) are collected during the validation process. One issue is the value of this data/information to the user - in respect to the fact that the user will be interested in the whole process of validation - how it was originally submitted, reviewed and then finally approved:
- Originally submitted documentation (completed against the validation specification)
- The validation report (outline any conditions that need to be addressed for the submission to be successful)
- The amended documentation (to meet the conditions that arose from the validation report)
- Response to validation conditions report (how successful the faculty was in meeting the conditions)
Key Meta-Data (requirements engineering)
The 'key' meta-data, for the time being, is the top level data about the documents - a good starting point is generic data collected through the Programme Specification Pro-Forma (Word): (the following includes possible additions suggested during the meeting)
- Teaching Institution (e.g. Staffordshire University, SURF, UK Non-SURF, Overseas)
- Accreditation / Professional / Statutory Body
- Final Award (e.g. CertHE, BA, BA (Hons), BSc)
- Programme Title
- UCAS Code(s)
- QAA Subject Benchmarking Group(s)
- Date of Production (validation)
- University Faculty / School
- Mode of Attendance / Delivery Method (e.g. PT. FT)
- Method of Delivery (e.g. Blended, Distance)
- THESIS / Award code
Recording Best Practice (eLearning Models)
This is an important part of the project and further discussions are required to establish what meta-data field(s) are required to disclose the type of eLearning model(s) that were used to inform the validation process - critical when looking at creating a 'fast-track' approach for courses that engage with technology supported learning (TSL).
Next steps
- Need to contact Sam Rowley / Ray Reid about Hive Repository Meta-data (technical queries) - specifically, searching for documents (inc. listing all documents that relate to each other) and XML Meta-data templates
- Further meeting to be arranged with Helen Walmsley about project requirements and direction of scoping this part of the project - in regard to what outputs are relevant and useful/ of value
- Investigate Meta-data standards further - in respect to library systems / university QAA systems
Tuesday, 3 June 2008
Getting Started!
The DIVAS project has started! The team are all very excited to be involved in such an interesting project that will save staff at the university time and effort in preparing for validation.
I've been working on the following:
* Developing the project plan
* Arranging and atttending the first steering group meeting
* Individual meetings with the team
* Setting up this blog!
I've been working on the following:
* Developing the project plan
* Arranging and atttending the first steering group meeting
* Individual meetings with the team
* Setting up this blog!
Subscribe to:
Comments (Atom)

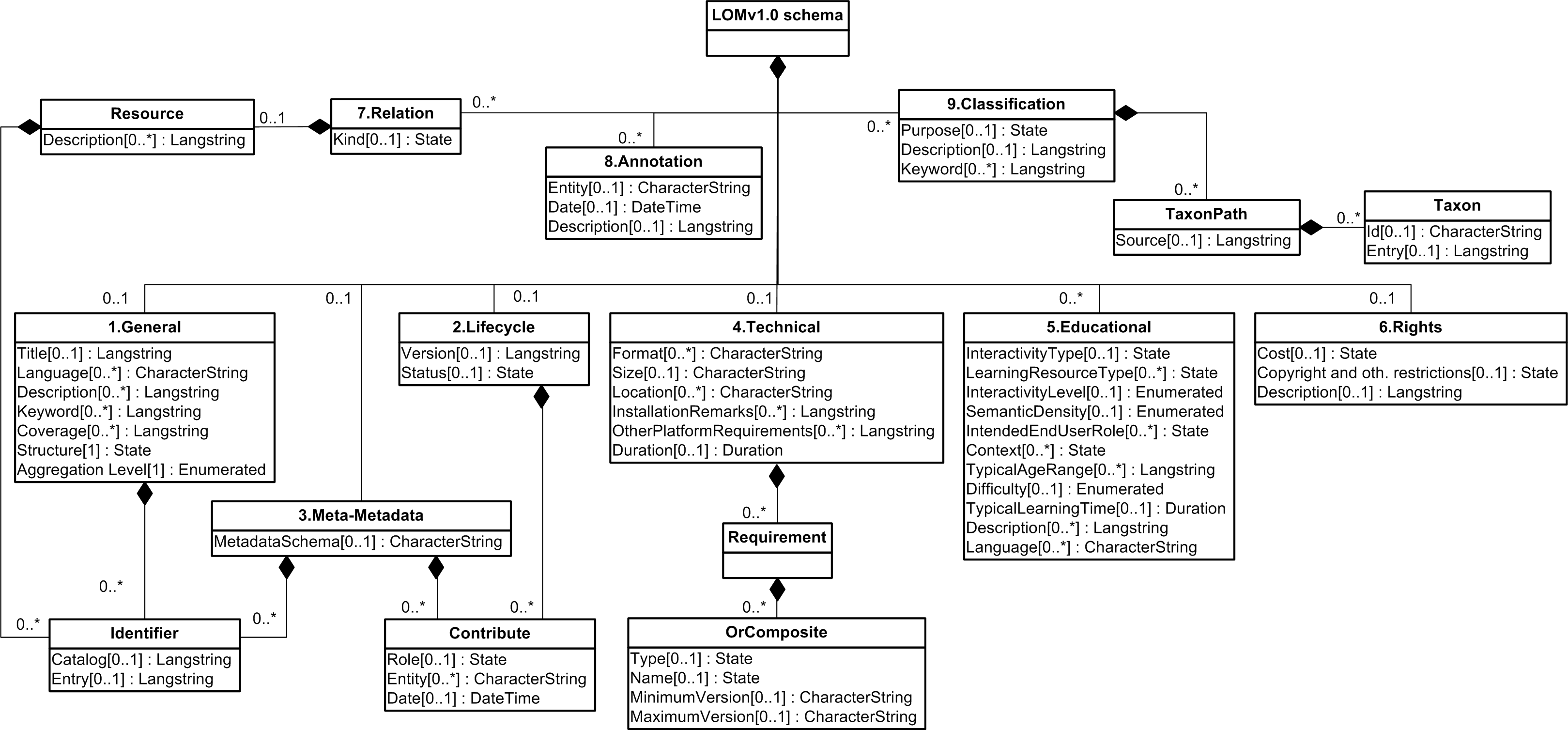{kind=link}